Data Curation?
데이터 큐레이션이란?
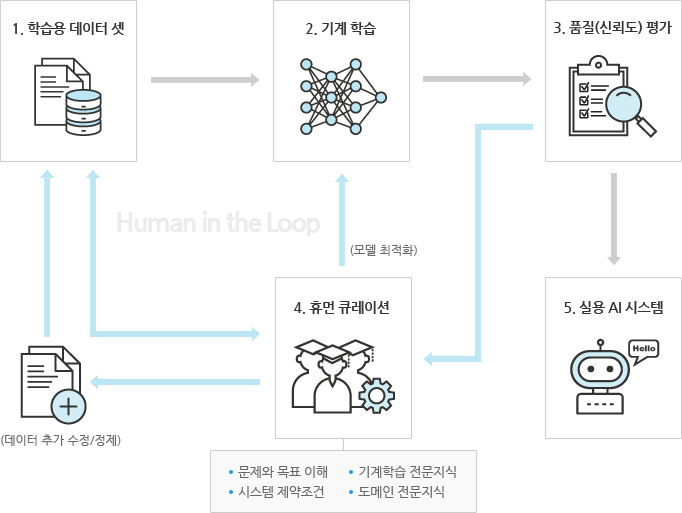
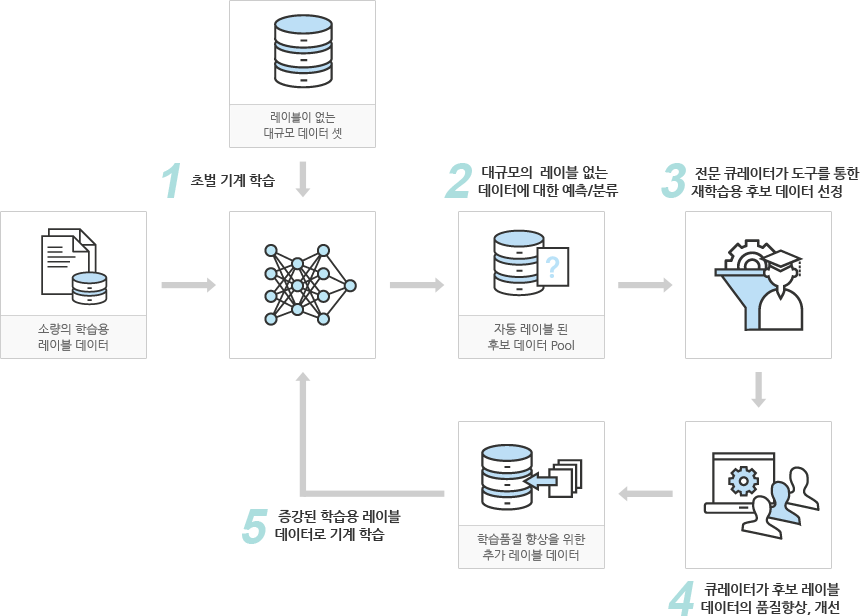
데이터 큐레이션은 데이터 수집과 정제에서 어노테이션과 분류, 학습용 데이터 생성 등 데이터의 활용 가치를 높이기 위한 모든 활동을 의미 합니다. 데이터 기반의 심층 분석과 기계학습을 위해서는 대규모 데이터의 확보뿐 아니라 기계가 읽고(readable), 학습하고(learnable), 의미 이해 가능한(understandable) 형태로 가공 되어야 합니다. 데이터믹시의 데이터 큐레이션 서비스는 솔트룩스 20년의 데이터 품질관리와 기계학습 경험이 축적된 세계 최고 수준의 데이터 서비스를 제공합니다.
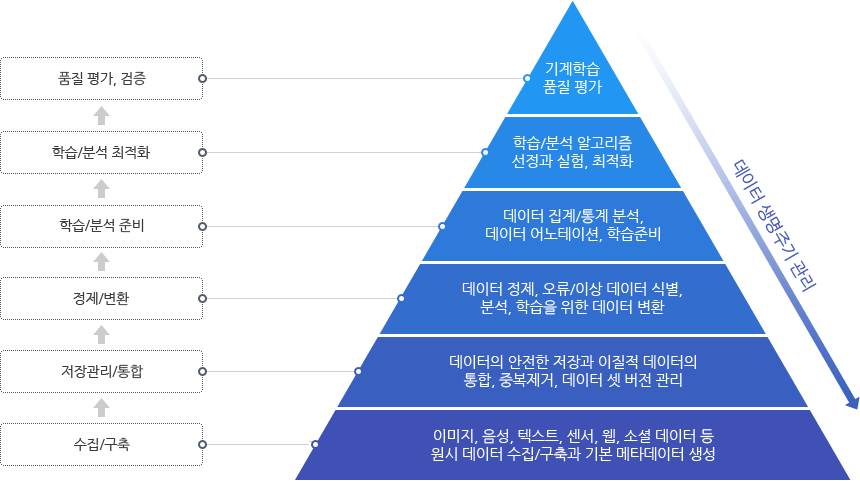
[ 데이터 사이언스를 위한 데이터 큐레이션 6단계 ]










분석타입
원본데이터란?
키워드에 대한 검색 결과 데이터로 분석에 사용되는 데이터 원본을 확인할 수 있다.
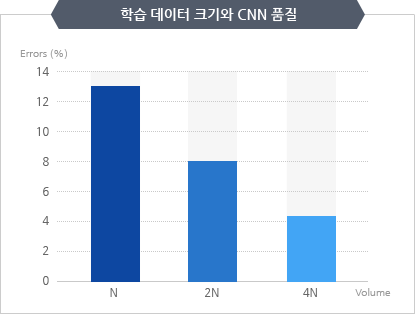
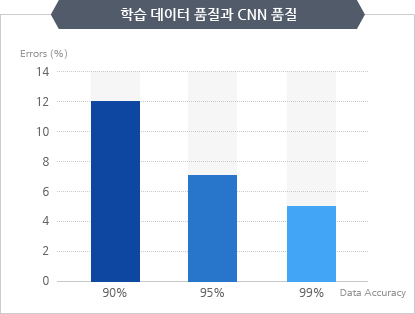
대표 차트
사용 가능한 차트들